The sample cluster in this chapter represents a simple, yet effective RAC cluster deployment. Where necessary, a rationale will be provided so that when your business requirements cause you to deviate from the sample cluster requirements, there will be information to help you with these customizations.
Oracle 10gR2 RAC can provide both high availability and scalability using modern commodity servers running RHEL4. Oracle 10gR2 comes in both 32-bit and 64-bit versions. A typical modern four node RAC cluster consists of high quality commodity servers that provide superior price/performance, reliability, and modularity to make Oracle commodity computing a viable alternative to large Enterprise class UNIX mainframes.
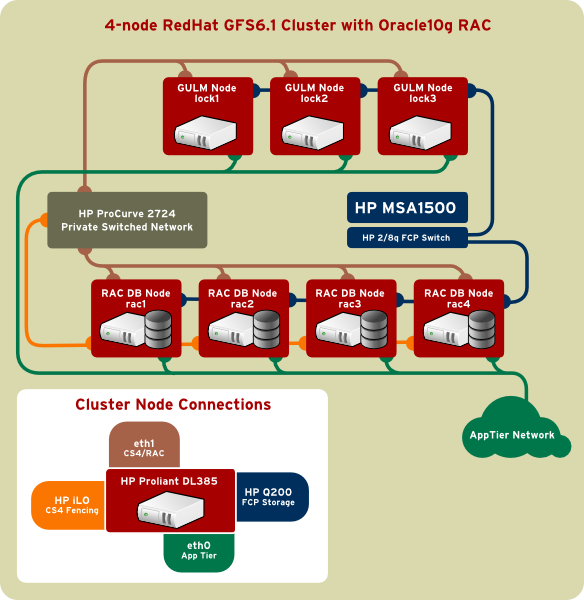
This sample cluster, which consists of four identical nodes, is the most common deployment topology. It is called a Symmetrical RAC cluster as all server nodes are identically configured.
Note
Asymmetrical cluster topologies also make sense where there is a need to isolate application writes to one node. Spreading writes over several nodes in RAC can limit scalability. It can complicate node failover, but this highlights how important application integration with the RAC is. Asymmetrical RAC clusters slightly favor performance over availability.
This cluster uses a commodity storage platform (HP Storageworks MSA1500) which is a conventional 2GB/s FCP SAN. GFS is a blocks-based clustered filesystem and therefore can run over any FCP or iSCSI SAN. The storage array must be accessible from all nodes. Each node needs a FCP HBA. Storage vendors will be very particular about which HBAs and which supported drivers are required for use with their equipment. Typically, the vendor will sell an attach kit that contains the FCP HBA and the RHEL4 relevant drivers.
A minimum of one FCP switch is required, although many topologies are configured with two switches, which would then require each node to have a dual-ported HBA.
Note
Like FCP, iSCSI is a blocks-based protocol that implements the T.10 SCSI command set. It does this over a TCP/IP transport instead of a Fiber Channel Transport. The term SAN and NAS are no longer relevant in the modern storage world, but have historically been euphemisms for SCSI over FCP (SAN) and NFS over TCP/IP (NAS). What matters is whether or not it is a SCSI blocks-based protocol or if it uses the NFS filesystem protocol when communicating with the storage array. Often iSCSI is mistakenly referred to as NAS, where it really has much more in common with FCP, since the protocol is what matters, not the transport.
In order for Oracle to perform well, it requires spindles, not bandwidth. Many customers often configure their storage array based on how much space the database might need or if they do consider performance, how much bandwidth. These are not appropriate metrics for sizing a storage array to run an Oracle database.
Database performance almost always depends on the number of IOPs (I/O Operations) that a storage fabric can deliver and this is inevitably a function of the number of spindles underneath a database table or index. The best strategy is to use the SAME (Strip and Mirror everything) methodology. This allows any GFS volume to have access to the maximum IOP rate the array supports without having the performance requirements of the application in advance.
When doing a SQL query that does an index range scan, thousands of IOPs may be needed. What determines the IOP rate of a given physical disk is how fast it spins (RPM), the location of the data and the interface type. Here is an approximate sizing guide:
| Interface/RPM | IOPs |
|---|---|
|
SATA-I (7200) |
50 IOPS |
|
SATA-II (10K) |
150 IOPS |
|
FCP 10K |
150 IOPs |
|
FCP 15K |
200 IOPs |
Table 1.1. Sizing Guide
A 144GB 10K FCP drive can sometimes out-perform a 72GB 10K drive because most of the data might be located in fewer “tracks,” causing the larger disk to seek less. However, the rotational latency is identical and the track cache often does not help as the database typically reads thousands of random blocks per second. SATA-I drives are particularly bad because they do not support tagged-queuing. Tagged queuing, an interface optimization found in SCSI, permits the disk to process more I/O transactions, but it increases the cost. A 7200-rpm Ultra-Wide SCSI disk often out-performs the equivalent SATA-I due to tagged queuing. SATA-I drives are very high capacity and cheap, but are very poor at random IOPS. SATA-II disks support tagged queuing.
A modern Oracle database should have at least two shelves (20-30 payload spindles) in order to insure that there is a reasonable amount of performance. In this cluster, the RAID10 volumes are implemented in the storage array, which is now common practice. The extent allocation policy does influence performance and this will be defined when the volume group is created with CLVM. CLVM will be presented with several physical LUNs that all have the same performance characteristics.
When adding performance capacity to the storage array, it is important that the array re-balance the existing allocated LUNs over this larger set of spindles so the database objects on those existing GFS volumes benefit from increased IOP rates.
Note
Payload spindles are the physical disks that contain only data, not parity. RAID 0+1 configurations allow the mirror to be utilized as payload, which doubles the IOP rate of a mirror. Some arrays that support this feature on conventional RAID1 mirrors also perform this optimization.
The Oracle Clusterware files (Voting and Registry) are not currently supported on GFS. For this cluster, two 256MB shared raw partitions located on LUN0 will be used. LUN0 is usually not susceptible to the device scanning instability, unless new SCSI adaptors are added to the node so not connect SCSI controllers to a RAC cluster node once Clusterware is installed. Since all candidate CLVMD2 LUNs have the same performance characteristics, their size and number is determined by their usage requirements:
-
One 6GB LUN (Shared Oracle Home)
-
One 24GB LUN for datafiles and indexes
-
Four 4GB LUNs for Redo logs and Undo tablespaces
Each node in the cluster gets a dedicated volume for their specific Redo and Undo. One single GFS volume will contain all datafiles and indexes. This normally will not cause a bottleneck on RHEL unless there is a requirement for more than 15,000 IOPs, but this is an operational trade-off of performance and simplicity in a modest cluster. The number of spindles in the array should continue to be the bottleneck.
Caution
Choosing a RAID policy can be contentious. With databases, spindle-count matters more than size, so using a simple RAID scheme such as RAID 1+0 (or RAID 10- mirrored, then striped) is often the best policy. It is faster on random I/O, yet not as space-efficient as RAID4 and RAID5. The system will typically have far more space because the array was correctly configured by spindle-count, not bandwidth or capacity.
Fencing is a mechanism a cluster employs to prevent un-coordinated activity to the shared storage array. It prevents “split-brain” clusters where some nodes think they are part of the actual cluster and another set thinks the same thing. This usually destroys the integrity of the shared storage. Fencing can be implemented in a variety of ways in CS4, but the one used in this sample cluster uses server IPMI (Integrated Power Management Interface). HP servers call this feature iLO (Integrated Lights Out) and it is found on all Proliant servers. This is a network accessible management processor that accepts commands that can power on and off the server.
In CS4, the lock servers are responsible for maintaining quorum and determining if a member node is in such a state that it needs to be fenced in order to protect the integrity of the cluster. The master lock server will issue commands directly to the power management interface to power cycle the server node. This is a very reliable fencing mechanism. CS4 supports a variety of hardware interfaces that can affect power cycling on nodes that need to be fenced.
The lock manager that is certified for use with Oracle 10gR2 is called GULM (Generic User mode Lock Manager). It is required that the lock managers be physically distinct servers; this is known as Remote Lock Management. The minimum requirement is to have at least three of them, with one master and two slaves. There are four RAC servers and three external GULM servers and all of them must capable of being fenced. The lock servers do not need to be as powerful as the database nodes. They should have at least 1GB of RAM and be GbE connected, but can run either 32-bit or 64-bit RHEL. The database nodes are HP DL385 dual-core, dual-socket four-way Opterons, and the lock servers could be less-equipped DL385s to simplfy the order—if all seven nodes are being purchased together. The lock servers could even be previous generation DL360s that meet the GbE and memory requirements.
Several network fabrics are required for both CS4 and Oracle to communicate across the cluster. These networks could all have their own private physical interfaces and network fabrics, but this sample cluster has overlapped the GULM and Oracle RAC heartbeat networks. The RAC heartbeat network is also used to move database blocks between nodes. Depending on the nature of the database application, it might be necessary to further dedicate a physical network just to the RAC heartbeat network. Only one GbE switch is used (HP ProCurve 2724) for both heartbeat fabrics and iLO.
Note
If more redundancy is required, then adding another switch requires adding two more GbE ports to each server in order to implement bonded interfaces. Just adding a 2nd private switch dedicated just to RAC does not help. If the other switch fails, then CS4 heartbeat would fail and take RAC down with it.
Note
Private unmanaged switches are sufficient as these are standalone, isolated network fabrics. Network Operations staff may still prefer that the switch is managed, but it should remain physically isolated from production VLANs.
For configuring CS4 and Oracle RAC, a hostname convention was followed to make it easier to map hostnames to a network. All networks are required and must map to underlying physical interfaces. The type and number of physical interfaces used is a performance and reliability consideration.
| Public | RAC vip | RAC heartbeat | CS4 heartbeat | iLO |
|---|---|---|---|---|
|
RAC1 |
RAC1-vip |
RAC1-priv |
RAC1-priv |
RAC1-iLO |
|
RAC2 |
RAC2-vip |
RAC2-priv |
RAC2-priv |
RAC2-iLO |
|
RAC3 |
RAC3-vip |
RAC3-priv |
RAC3-priv |
RAC3-iLO |
|
RAC4 |
RAC4-vip |
RAC4-priv |
RAC4-priv |
RAC4-iLO |
|
Lock1 |
n/a |
n/a |
Lock1-gulm |
Lock1-iLO |
|
Lock2 |
n/a |
n/a |
Lock2-gulm |
Lock2-iLO |
|
Lock3 |
n/a |
n/a |
Lock3-gulm |
Lock3-iLO |
Table 1.2. Hostnames and Networks